32 KiB
CogVideo & CogVideoX
🤗 Huggingface Space または 🤖 ModelScope Space で CogVideoX-5B モデルをオンラインで体験してください
📍 清影 と APIプラットフォーム を訪問して、より大規模な商用ビデオ生成モデルを体験.
更新とニュース
- 🔥🔥
2025/03/24: CogKit は CogView4 および CogVideoX シリーズの微調整と推論のためのフレームワークです。このツールキットを活用することで、私たちのマルチモーダル生成モデルを最大限に活用できます。 - ニュース:
2025/02/28: DDIM Inverse がCogVideoX-5BとCogVideoX1.5-5Bでサポートされました。詳細は こちら をご覧ください。 - ニュース:
2025/01/08: 私たちはdiffusersバージョンのモデルをベースにしたLora微調整用のコードを更新しました。より少ないVRAM(ビデオメモリ)で動作します。詳細についてはこちらをご覧ください。 - ニュース:
2024/11/15:CogVideoX1.5モデルのdiffusersバージョンをリリースしました。わずかなパラメータ調整で以前のコードをそのまま利用可能です。 - ニュース:
2024/11/08:CogVideoX1.5モデルをリリースしました。CogVideoX1.5 は CogVideoX オープンソースモデルのアップグレードバージョンです。 CogVideoX1.5-5B シリーズモデルは、10秒 長の動画とより高い解像度をサポートしており、CogVideoX1.5-5B-I2Vは任意の解像度での動画生成に対応しています。 SAT コードはすでに更新されており、diffusersバージョンは現在適応中です。 SAT バージョンのコードは こちら からダウンロードできます。 - 🔥 ニュース:
2024/10/13: コスト削減のため、単一の4090 GPUでCogVideoX-5Bを微調整できるフレームワーク cogvideox-factory がリリースされました。複数の解像度での微調整に対応しています。ぜひご利用ください! - 🔥ニュース:
2024/10/10: 技術報告書を更新し、より詳細なトレーニング情報とデモを追加しました。 - 🔥 ニュース:
2024/10/10: 技術報告書を更新しました。こちら をクリックしてご覧ください。さらにトレーニングの詳細とデモを追加しました。デモを見るにはこちら をクリックしてください。 - 🔥ニュース:
2024/10/09: 飛書の技術ドキュメント でCogVideoXの微調整ガイドを公開しています。分配の自由度をさらに高めるため、公開されているドキュメント内のすべての例が完全に再現可能です。 - 🔥ニュース:
2024/9/19: CogVideoXシリーズの画像生成ビデオモデル CogVideoX-5B-I2V をオープンソース化しました。このモデルは、画像を背景入力として使用し、プロンプトワードと組み合わせてビデオを生成することができ、より高い制御性を提供します。これにより、CogVideoXシリーズのモデルは、テキストからビデオ生成、ビデオの継続、画像からビデオ生成の3つのタスクをサポートするようになりました。オンラインでの体験 をお楽しみください。 - 🔥 ニュース:
2024/9/19: CogVideoXのトレーニングプロセスでビデオデータをテキスト記述に変換するために使用されるキャプションモデル CogVLM2-Caption をオープンソース化しました。ダウンロードしてご利用ください。 - 🔥
2024/8/27: CogVideoXシリーズのより大きなモデル CogVideoX-5B をオープンソース化しました。モデルの推論性能を大幅に最適化し、推論のハードルを大幅に下げました。GTX 1080TIなどの旧型GPUで CogVideoX-2B を、RTX 3060などのデスクトップGPUで CogVideoX-5B モデルを実行できます。依存関係を更新・インストールするために、要件 を厳守し、推論コードは cli_demo を参照してください。さらに、CogVideoX-2B モデルのオープンソースライセンスが Apache 2.0 ライセンス に変更されました。 - 🔥
2024/8/6: CogVideoX-2B 用の 3D Causal VAE をオープンソース化しました。これにより、ビデオをほぼ無損失で再構築することができます。 - 🔥
2024/8/6: CogVideoXシリーズのビデオ生成モデルの最初のモデル、CogVideoX-2B をオープンソース化しました。 - 🌱 ソース:
2022/5/19: CogVideoビデオ生成モデルをオープンソース化しました(現在、CogVideoブランチで確認できます)。これは、トランスフォーマーに基づく初のオープンソース大規模テキスト生成ビデオモデルです。技術的な詳細については、ICLR'23論文 をご覧ください。
より強力なモデルが、より大きなパラメータサイズで登場予定です。お楽しみに!
目次
特定のセクションにジャンプ:
クイックスタート
プロンプトの最適化
モデルを実行する前に、こちら を参考にして、GLM-4(または同等の製品、例えばGPT-4)の大規模モデルを使用してどのようにモデルを最適化するかをご確認ください。これは非常に重要です。モデルは長いプロンプトでトレーニングされているため、良いプロンプトがビデオ生成の品質に直接影響を与えます。
SAT
sat_demo の指示に従ってください: SATウェイトの推論コードと微調整コードが含まれています。CogVideoXモデル構造に基づいて改善することをお勧めします。革新的な研究者は、このコードを使用して迅速なスタッキングと開発を行うことができます。
Diffusers
pip install -r requirements.txt
次に diffusers_demo を参照してください: 推論コードの詳細な説明が含まれており、一般的なパラメータの意味についても言及しています。
量子化推論の詳細については、diffusers-torchao を参照してください。Diffusers と TorchAO を使用することで、量子化推論も可能となり、メモリ効率の良い推論や、コンパイル時に場合によっては速度の向上が期待できます。A100 および H100 上でのさまざまな設定におけるメモリおよび時間のベンチマークの完全なリストは、diffusers-torchao に公開されています。
Gallery
CogVideoX-5B
CogVideoX-2B
ギャラリーの対応するプロンプトワードを表示するには、こちらをクリックしてください
モデル紹介
CogVideoXは、清影 と同源のオープンソース版ビデオ生成モデルです。 以下の表に、提供しているビデオ生成モデルの基本情報を示します:
| モデル名 | CogVideoX1.5-5B (最新) | CogVideoX1.5-5B-I2V (最新) | CogVideoX-2B | CogVideoX-5B | CogVideoX-5B-I2V |
|---|---|---|---|---|---|
| 公開日 | 2024年11月8日 | 2024年11月8日 | 2024年8月6日 | 2024年8月27日 | 2024年9月19日 |
| ビデオ解像度 | 1360 * 768 | Min(W, H) = 768 768 ≤ Max(W, H) ≤ 1360 Max(W, H) % 16 = 0 |
720 * 480 | ||
| フレーム数 | 16N + 1 (N <= 10) である必要があります (デフォルト 81) | 8N + 1 (N <= 6) である必要があります (デフォルト 49) | |||
| 推論精度 | BF16(推奨), FP16, FP32,FP8*,INT8,INT4非対応 | FP16*(推奨), BF16, FP32,FP8*,INT8,INT4非対応 | BF16(推奨), FP16, FP32,FP8*,INT8,INT4非対応 | ||
| 単一GPUメモリ消費量 |
SAT BF16: 76GB diffusers BF16:10GBから* diffusers INT8(torchao):7GBから* |
SAT FP16: 18GB diffusers FP16: 4GB以上* diffusers INT8(torchao): 3.6GB以上* |
SAT BF16: 26GB diffusers BF16 : 5GB以上* diffusers INT8(torchao): 4.4GB以上* |
||
| 複数GPU推論メモリ消費量 | BF16: 24GB* using diffusers |
FP16: 10GB* diffusers使用 |
BF16: 15GB* diffusers使用 |
||
| 推論速度 (Step = 50, FP/BF16) |
シングルA100: ~1000秒(5秒ビデオ) シングルH100: ~550秒(5秒ビデオ) |
シングルA100: ~90秒 シングルH100: ~45秒 |
シングルA100: ~180秒 シングルH100: ~90秒 |
||
| プロンプト言語 | 英語* | ||||
| プロンプト長さの上限 | 224トークン | 226トークン | |||
| ビデオ長さ | 5秒または10秒 | 6秒 | |||
| フレームレート | 16フレーム/秒 | 8フレーム/秒 | |||
| 位置エンコーディング | 3d_rope_pos_embed | 3d_sincos_pos_embed | 3d_rope_pos_embed | 3d_rope_pos_embed + learnable_pos_embed | |
| ダウンロードリンク (Diffusers) | 🤗 HuggingFace 🤖 ModelScope 🟣 WiseModel |
🤗 HuggingFace 🤖 ModelScope 🟣 WiseModel |
🤗 HuggingFace 🤖 ModelScope 🟣 WiseModel |
🤗 HuggingFace 🤖 ModelScope 🟣 WiseModel |
🤗 HuggingFace 🤖 ModelScope 🟣 WiseModel |
| ダウンロードリンク (SAT) | 🤗 HuggingFace 🤖 ModelScope 🟣 WiseModel |
SAT | |||
データ解説
- diffusersライブラリを使用してテストする際には、
diffusersライブラリが提供する全ての最適化が有効になっています。この方法は NVIDIA A100 / H100以外のデバイスでのメモリ/メモリ消費のテストは行っていません。通常、この方法はNVIDIA Ampereアーキテクチャ 以上の全てのデバイスに適応できます。最適化を無効にすると、メモリ消費は倍増し、ピークメモリ使用量は表の3倍になりますが、速度は約3〜4倍向上します。以下の最適化を部分的に無効にすることが可能です:
pipe.enable_sequential_cpu_offload()
pipe.vae.enable_slicing()
pipe.vae.enable_tiling()
- マルチGPUで推論する場合、
enable_sequential_cpu_offload()最適化を無効にする必要があります。 - INT8モデルを使用すると推論速度が低下しますが、これはメモリの少ないGPUで正常に推論を行い、ビデオ品質の損失を最小限に抑えるための措置です。推論速度は大幅に低下します。
- CogVideoX-2Bモデルは
FP16精度でトレーニングされており、CogVideoX-5BモデルはBF16精度でトレーニングされています。推論時にはモデルがトレーニングされた精度を使用することをお勧めします。 - PytorchAOおよびOptimum-quanto
は、CogVideoXのメモリ要件を削減するためにテキストエンコーダ、トランスフォーマ、およびVAEモジュールを量子化するために使用できます。これにより、無料のT4
Colabやより少ないメモリのGPUでモデルを実行することが可能になります。同様に重要なのは、TorchAOの量子化は
torch.compileと完全に互換性があり、推論速度を大幅に向上させることができる点です。NVIDIA H100およびそれ以上のデバイスではFP8精度を使用する必要があります。これには、torch、torchaoPythonパッケージのソースコードからのインストールが必要です。CUDA 12.4の使用をお勧めします。 - 推論速度テストも同様に、上記のメモリ最適化方法を使用しています。メモリ最適化を使用しない場合、推論速度は約10%向上します。
diffusersバージョンのモデルのみが量子化をサポートしています。 - モデルは英語入力のみをサポートしており、他の言語は大規模モデルの改善を通じて英語に翻訳できます。
友好的リンク
コミュニティからの貢献を大歓迎し、私たちもオープンソースコミュニティに積極的に貢献しています。以下の作品はすでにCogVideoXに対応しており、ぜひご利用ください:
- RIFLEx-CogVideoX: RIFLExは動画の長さを外挿する手法で、たった1行のコードで動画の長さを元の2倍に延長できます。RIFLExはトレーニング不要の推論をサポートするだけでなく、CogVideoXをベースにファインチューニングしたモデルも提供しています。元の長さの動画でわずか1000ステップのファインチューニングを行うだけで、長さ外挿能力を大幅に向上させることができます。
- CogVideoX-Fun: CogVideoX-Funは、CogVideoXアーキテクチャを基にした改良パイプラインで、自由な解像度と複数の起動方法をサポートしています。
- CogStudio: CogVideo の Gradio Web UI の別のリポジトリ。より高機能な Web UI をサポートします。
- Xorbits Inference: 強力で包括的な分散推論フレームワークであり、ワンクリックで独自のモデルや最新のオープンソースモデルを簡単にデプロイできます。
- ComfyUI-CogVideoXWrapper ComfyUIフレームワークを使用して、CogVideoXをワークフローに統合します。
- VideoSys: VideoSysは、使いやすく高性能なビデオ生成インフラを提供し、最新のモデルや技術を継続的に統合しています。
- AutoDLイメージ: コミュニティメンバーが提供するHuggingface Spaceイメージのワンクリックデプロイメント。
- インテリアデザイン微調整モデル: は、CogVideoXを基盤にした微調整モデルで、インテリアデザイン専用に設計されています。
- xDiT: xDiTは、複数のGPUクラスター上でDiTsを並列推論するためのエンジンです。xDiTはリアルタイムの画像およびビデオ生成サービスをサポートしています。
- CogVideoX-Interpolation: キーフレーム補間生成において、より大きな柔軟性を提供することを目的とした、CogVideoX構造を基にした修正版のパイプライン。
- DiffSynth-Studio: DiffSynth Studioは、拡散エンジンです。テキストエンコーダー、UNet、VAEなどを含むアーキテクチャを再構築し、オープンソースコミュニティモデルとの互換性を維持しつつ、計算性能を向上させました。このフレームワークはCogVideoXに適応しています。
- CogVideoX-Controlnet: CogVideoXモデルを含むシンプルなControlNetモジュールのコード。
- VideoTuna: VideoTuna は、テキストからビデオ、画像からビデオ、テキストから画像生成のための複数のAIビデオ生成モデルを統合した最初のリポジトリです。
- ConsisID: 一貫性のある顔を保持するために、周波数分解を使用するCogVideoX-5Bに基づいたアイデンティティ保持型テキストから動画生成モデル。
- ステップバイステップチュートリアル: WindowsおよびクラウドでのCogVideoX1.5-5B-I2Vモデルのインストールと最適化に関するステップバイステップガイド。FurkanGozukara氏の尽力とサポートに感謝いたします!
プロジェクト構造
このオープンソースリポジトリは、CogVideoX オープンソースモデルの基本的な使用方法と微調整の例を迅速に開始するためのガイドです。
Colabでのクイックスタート
無料のColab T4上で直接実行できる3つのプロジェクトを提供しています。
- CogVideoX-5B-T2V-Colab.ipynb: CogVideoX-5B テキストからビデオへの生成用Colabコード。
- CogVideoX-5B-T2V-Int8-Colab.ipynb: CogVideoX-5B テキストからビデオへの量子化推論用Colabコード。1回の実行に約30分かかります。
- CogVideoX-5B-I2V-Colab.ipynb: CogVideoX-5B 画像からビデオへの生成用Colabコード。
- CogVideoX-5B-V2V-Colab.ipynb: CogVideoX-5B ビデオからビデオへの生成用Colabコード。
Inference
- cli_demo: 推論コードの詳細な説明が含まれており、一般的なパラメータの意味についても言及しています。
- cli_demo_quantization: 量子化モデル推論コードで、低メモリのデバイスでも実行可能です。また、このコードを変更して、FP8 精度の CogVideoX モデルの実行をサポートすることもできます。
- diffusers_vae_demo: VAE推論コードの実行には現在71GBのメモリが必要ですが、将来的には最適化される予定です。
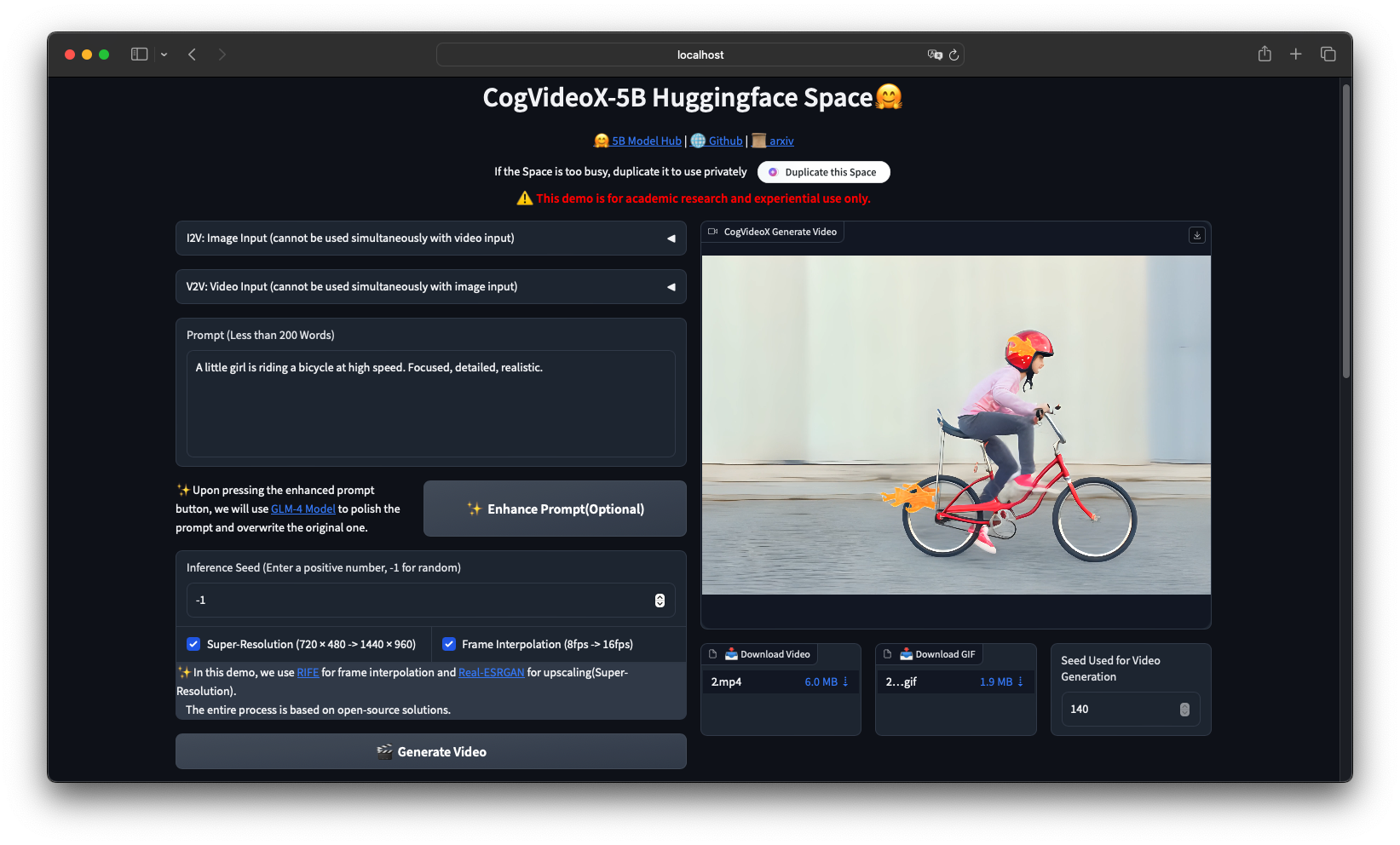
- space demo: Huggingface Spaceと同じGUIコードで、フレーム補間や超解像ツールが組み込まれています。
- convert_demo: ユーザー入力をCogVideoXに適した形式に変換する方法。CogVideoXは長いキャプションでトレーニングされているため、入力テキストをLLMを使用してトレーニング分布と一致させる必要があります。デフォルトではGLM-4を使用しますが、GPT、Geminiなどの他のLLMに置き換えることもできます。
- gradio_web_demo: CogVideoX-2B / 5B モデルを使用して動画を生成する方法を示す、シンプルな Gradio Web UI デモです。私たちの Huggingface Space と同様に、このスクリプトを使用して Web デモを起動することができます。
finetune
- train_cogvideox_lora: CogVideoX diffusers 微調整方法の詳細な説明が含まれています。このコードを使用して、自分のデータセットで CogVideoX を微調整することができます。
sat
- sat_demo: SATウェイトの推論コードと微調整コードが含まれています。CogVideoXモデル構造に基づいて改善することをお勧めします。革新的な研究者は、このコードを使用して迅速なスタッキングと開発を行うことができます。
ツール
このフォルダには、モデル変換/キャプション生成などのツールが含まれています。
- convert_weight_sat2hf: SAT モデルの重みを Huggingface モデルの重みに変換します。
- caption_demo: Caption ツール、ビデオを理解してテキストで出力するモデル。
- export_sat_lora_weight: SAT ファインチューニングモデルのエクスポートツール、SAT Lora Adapter を diffusers 形式でエクスポートします。
- load_cogvideox_lora: diffusers 版のファインチューニングされた Lora Adapter をロードするためのツールコード。
- llm_flux_cogvideox: オープンソースのローカル大規模言語モデル + Flux + CogVideoX を使用して自動的に動画を生成します。
- parallel_inference_xdit: xDiT によってサポートされ、ビデオ生成プロセスを複数の GPU で並列化します。
- cogvideox-factory: CogVideoXの低コスト微調整フレームワークで、
diffusersバージョンのモデルに適応しています。より多くの解像度に対応し、単一の4090 GPUでCogVideoX-5Bの微調整が可能です。
CogVideo(ICLR'23)
論文の公式リポジトリ: CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers は CogVideo branch にあります。
CogVideoは比較的高フレームレートのビデオを生成することができます。 32フレームの4秒間のクリップが以下に示されています。


CogVideoのデモは https://models.aminer.cn/cogvideo で体験できます。 元の入力は中国語です。
引用
🌟 私たちの仕事が役立つと思われた場合、ぜひスターを付けていただき、論文を引用してください。
@article{yang2024cogvideox,
title={CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer},
author={Yang, Zhuoyi and Teng, Jiayan and Zheng, Wendi and Ding, Ming and Huang, Shiyu and Xu, Jiazheng and Yang, Yuanming and Hong, Wenyi and Zhang, Xiaohan and Feng, Guanyu and others},
journal={arXiv preprint arXiv:2408.06072},
year={2024}
}
@article{hong2022cogvideo,
title={CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers},
author={Hong, Wenyi and Ding, Ming and Zheng, Wendi and Liu, Xinghan and Tang, Jie},
journal={arXiv preprint arXiv:2205.15868},
year={2022}
}
ライセンス契約
このリポジトリのコードは Apache 2.0 License の下で公開されています。
CogVideoX-2B モデル (対応するTransformersモジュールやVAEモジュールを含む) は Apache 2.0 License の下で公開されています。
CogVideoX-5B モデル(Transformers モジュール、画像生成ビデオとテキスト生成ビデオのバージョンを含む) は CogVideoX LICENSE の下で公開されています。