mirror of
https://github.com/kkroening/ffmpeg-python.git
synced 2026-06-14 09:38:14 +08:00
* Import ABC from collections.abc instead of collections for Python 3.9 compatibility. * Fix deprecation warnings due to invalid escape sequences. * Support Python 3.10 Co-authored-by: Karl Kroening <karlk@kralnet.us>
{kind=link}
Examples
Get video info (ffprobe)
probe = ffmpeg.probe(args.in_filename)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
width = int(video_stream['width'])
height = int(video_stream['height'])
Generate thumbnail for video

(
ffmpeg
.input(in_filename, ss=time)
.filter('scale', width, -1)
.output(out_filename, vframes=1)
.run()
)
Convert video to numpy array
out, _ = (
ffmpeg
.input('in.mp4')
.output('pipe:', format='rawvideo', pix_fmt='rgb24')
.run(capture_stdout=True)
)
video = (
np
.frombuffer(out, np.uint8)
.reshape([-1, height, width, 3])
)
Read single video frame as jpeg through pipe

out, _ = (
ffmpeg
.input(in_filename)
.filter('select', 'gte(n,{})'.format(frame_num))
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)
Convert sound to raw PCM audio
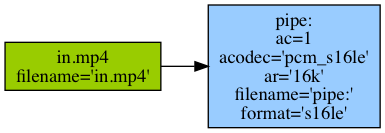
out, _ = (ffmpeg
.input(in_filename, **input_kwargs)
.output('-', format='s16le', acodec='pcm_s16le', ac=1, ar='16k')
.overwrite_output()
.run(capture_stdout=True)
)
Assemble video from sequence of frames
(
ffmpeg
.input('/path/to/jpegs/*.jpg', pattern_type='glob', framerate=25)
.output('movie.mp4')
.run()
)
With additional filtering:

(
ffmpeg
.input('/path/to/jpegs/*.jpg', pattern_type='glob', framerate=25)
.filter('deflicker', mode='pm', size=10)
.filter('scale', size='hd1080', force_original_aspect_ratio='increase')
.output('movie.mp4', crf=20, preset='slower', movflags='faststart', pix_fmt='yuv420p')
.view(filename='filter_graph')
.run()
)
Audio/video pipeline
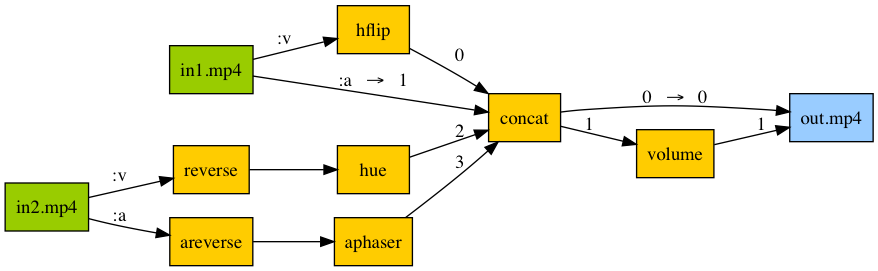
in1 = ffmpeg.input('in1.mp4')
in2 = ffmpeg.input('in2.mp4')
v1 = in1.video.hflip()
a1 = in1.audio
v2 = in2.video.filter('reverse').filter('hue', s=0)
a2 = in2.audio.filter('areverse').filter('aphaser')
joined = ffmpeg.concat(v1, a1, v2, a2, v=1, a=1).node
v3 = joined[0]
a3 = joined[1].filter('volume', 0.8)
out = ffmpeg.output(v3, a3, 'out.mp4')
out.run()
Mono to stereo with offsets and video

audio_left = (
ffmpeg
.input('audio-left.wav')
.filter('atrim', start=5)
.filter('asetpts', 'PTS-STARTPTS')
)
audio_right = (
ffmpeg
.input('audio-right.wav')
.filter('atrim', start=10)
.filter('asetpts', 'PTS-STARTPTS')
)
input_video = ffmpeg.input('input-video.mp4')
(
ffmpeg
.filter((audio_left, audio_right), 'join', inputs=2, channel_layout='stereo')
.output(input_video.video, 'output-video.mp4', shortest=None, vcodec='copy')
.overwrite_output()
.run()
)
Jupyter Frame Viewer

Jupyter Stream Editor
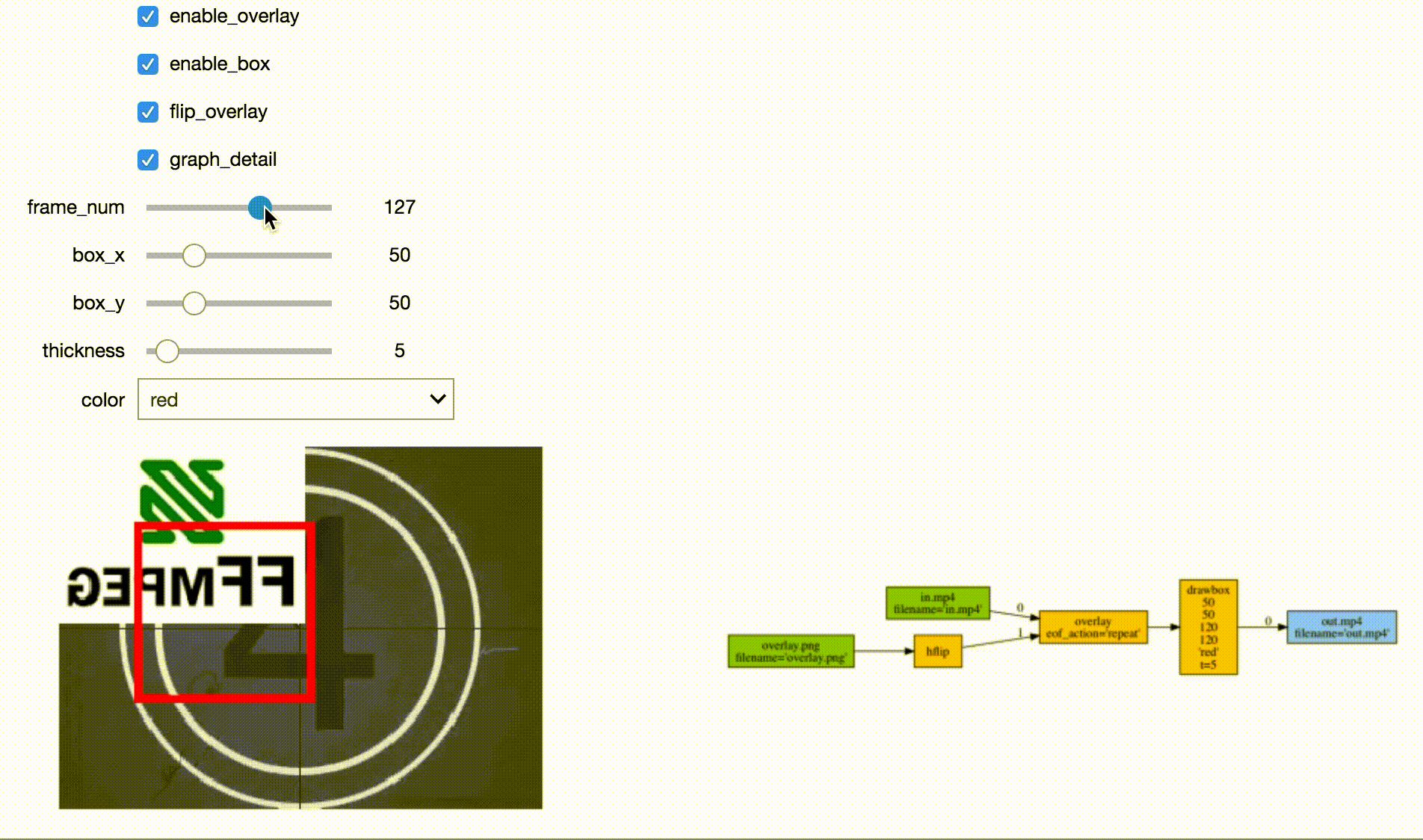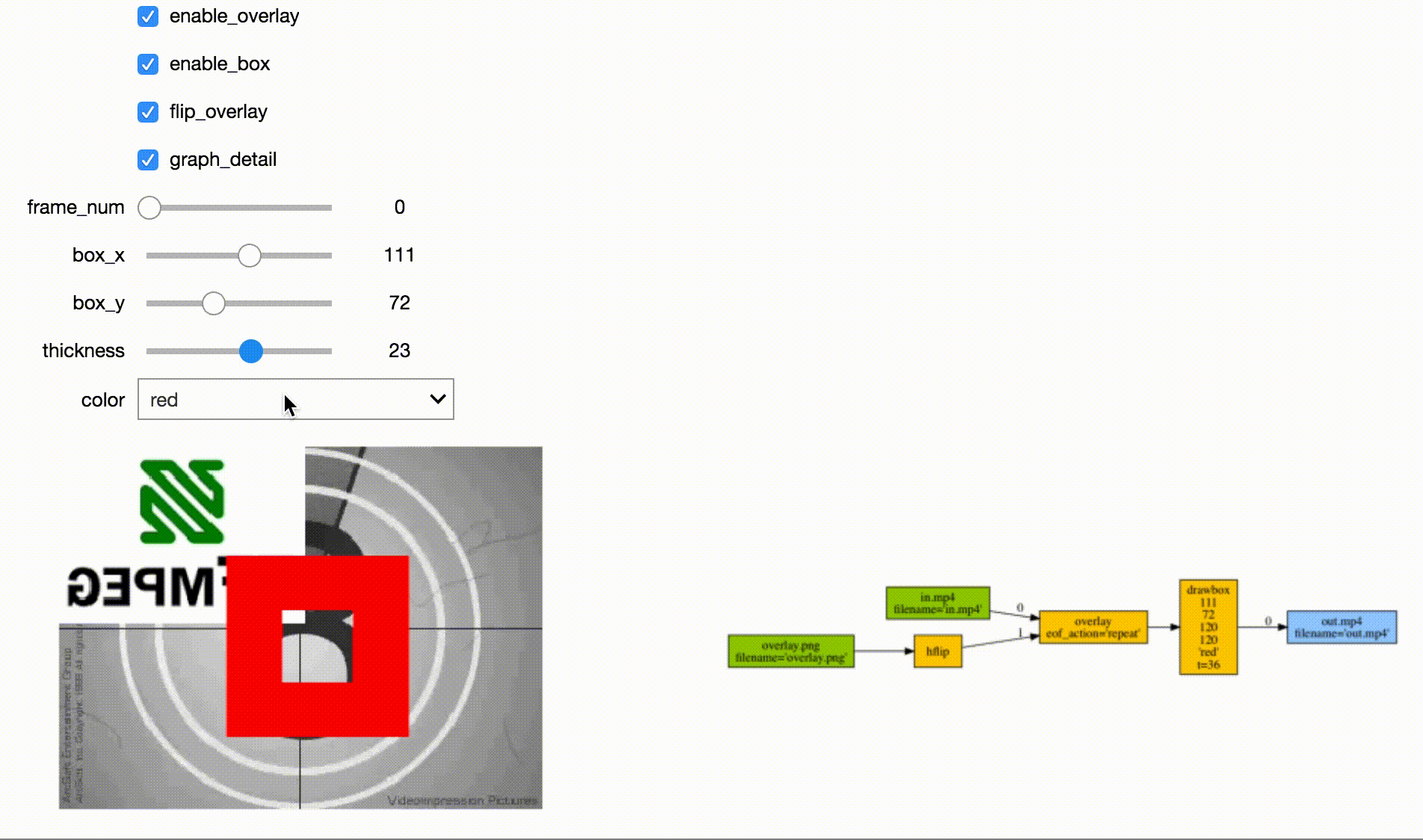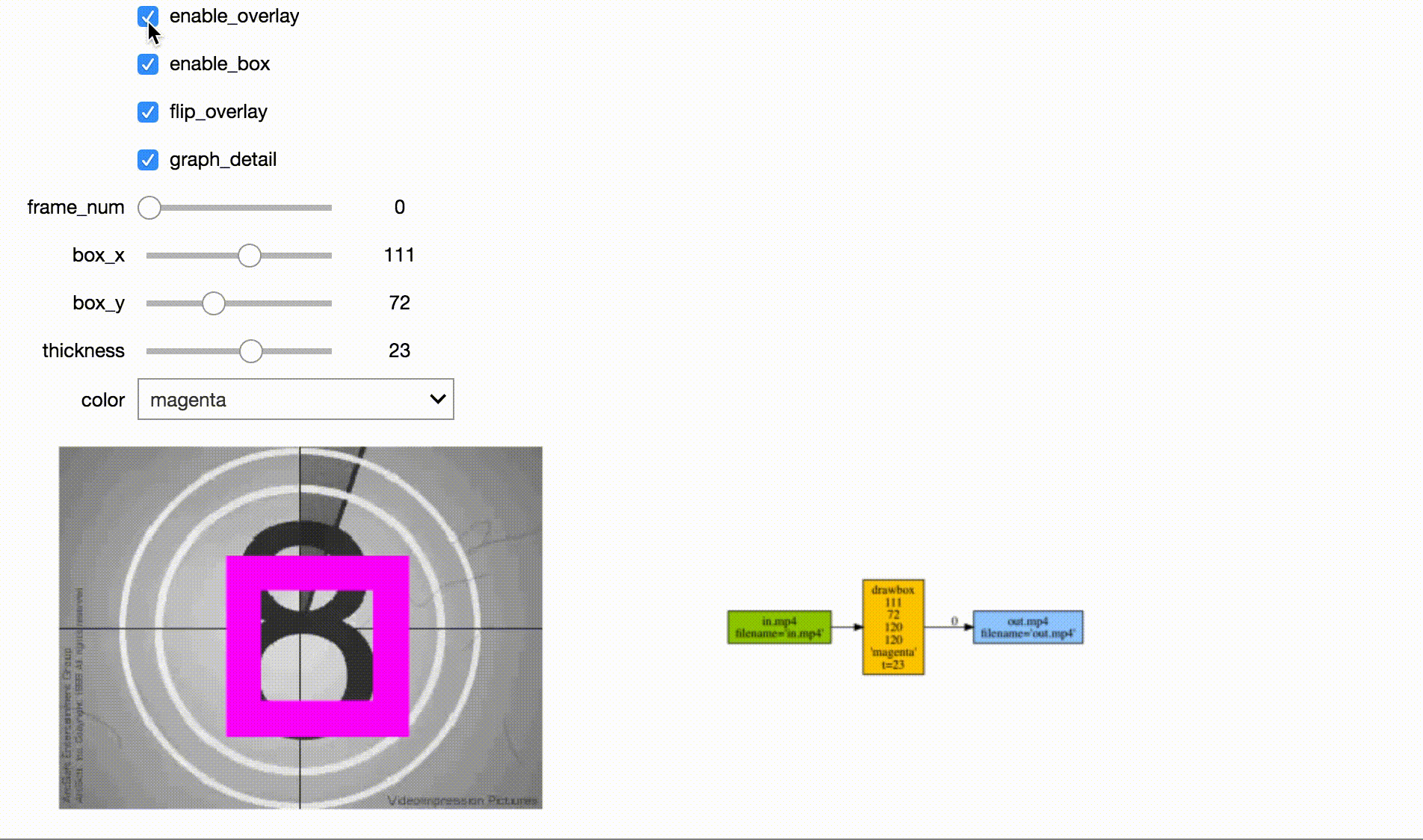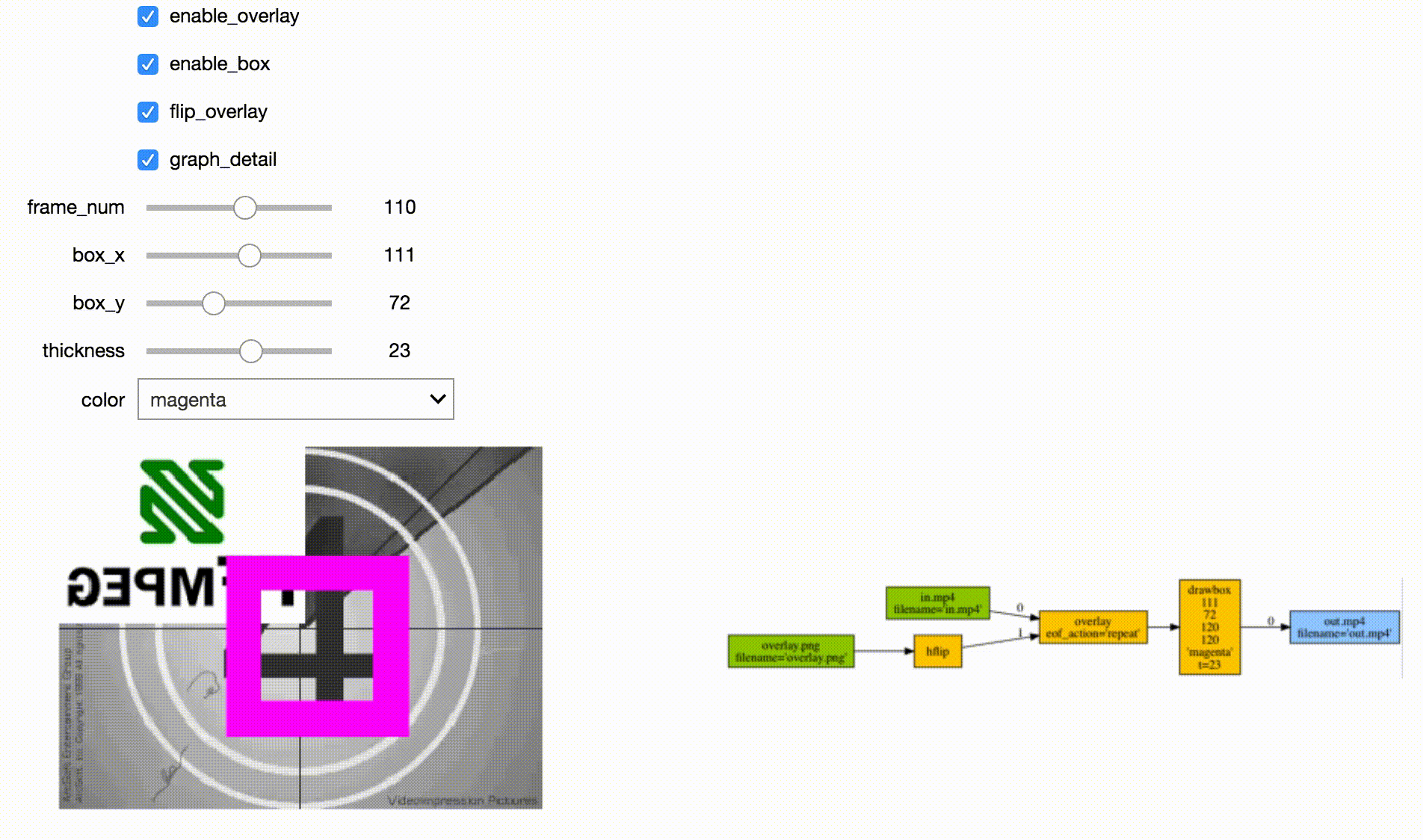
Tensorflow Streaming
- Decode input video with ffmpeg
- Process video with tensorflow using "deep dream" example
- Encode output video with ffmpeg
process1 = (
ffmpeg
.input(in_filename)
.output('pipe:', format='rawvideo', pix_fmt='rgb24', vframes=8)
.run_async(pipe_stdout=True)
)
process2 = (
ffmpeg
.input('pipe:', format='rawvideo', pix_fmt='rgb24', s='{}x{}'.format(width, height))
.output(out_filename, pix_fmt='yuv420p')
.overwrite_output()
.run_async(pipe_stdin=True)
)
while True:
in_bytes = process1.stdout.read(width * height * 3)
if not in_bytes:
break
in_frame = (
np
.frombuffer(in_bytes, np.uint8)
.reshape([height, width, 3])
)
# See examples/tensorflow_stream.py:
out_frame = deep_dream.process_frame(in_frame)
process2.stdin.write(
out_frame
.astype(np.uint8)
.tobytes()
)
process2.stdin.close()
process1.wait()
process2.wait()

FaceTime webcam input (OS X)
(
ffmpeg
.input('FaceTime', format='avfoundation', pix_fmt='uyvy422', framerate=30)
.output('out.mp4', pix_fmt='yuv420p', vframes=100)
.run()
)
Stream from a local video to HTTP server
video_format = "flv"
server_url = "http://127.0.0.1:8080"
process = (
ffmpeg
.input("input.mp4")
.output(
server_url,
codec = "copy", # use same codecs of the original video
listen=1, # enables HTTP server
f=video_format)
.global_args("-re") # argument to act as a live stream
.run()
)
to receive the video you can use ffplay in the terminal:
$ ffplay -f flv http://localhost:8080
Stream from RTSP server to TCP socket
packet_size = 4096
process = (
ffmpeg
.input('rtsp://%s:8554/default')
.output('-', format='h264')
.run_async(pipe_stdout=True)
)
while process.poll() is None:
packet = process.stdout.read(packet_size)
try:
tcp_socket.send(packet)
except socket.error:
process.stdout.close()
process.wait()
break